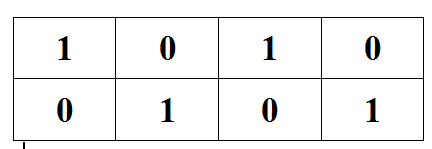Построение таблицы истинности двумя способами.
В этот статье будут показаны примеры заполнения таблиц истинности двоичными наборами без вычислений значений каких бы то ни было булевых функциях на них. Я предполагаю, что читатель уже знаком с сопутствующей терминологией и двоичной системой счисления (далее — 2СС), поэтому не буду прояснять эти термины и рассказывать о переводе чисел из одной системы счисления в другую.
Итак, перед тем, как построить таблицу истинности, следует определиться с количеством строк и столбцов в ней.
Количество столбцов будет равно количеству переменных функции плюс один столбец на значение функции на двоичных наборах.
Количество строк в таблице (количество двоичных наборов) будет вычисляться по формуле 2n, где n — количество переменных функции. Ещё одна дополнительная строка отводится на шапку таблицы, куда записываются имена переменных и имя вычисляемой функции (или её аналитическое выражение). То есть, можно сказать, общее количество строк таблицы с учётом шапки будет равно 2n + 1.
Рассмотрим пример. Пусть дана функция трёх переменных F(x, y, z) (n = 3). Начертим таблицу для этой функции, но пока не будем заполнять. Итак, общее количество строк будет равно 23 + 1 = 9, один из которых отводится на шапку. Количество столбцов таблицы будет равно количеству переменных (три переменные) да плюс ещё один на значения функции. Итого 4 столбца. Имеем такую таблицу:
Первый способ («по горизонтали»).
Он основан на использовании 2СС. Полагаю, это стандартный способ, которым пользуются в большинстве случаев при решении задач, предполагающих использование таблиц истинности.
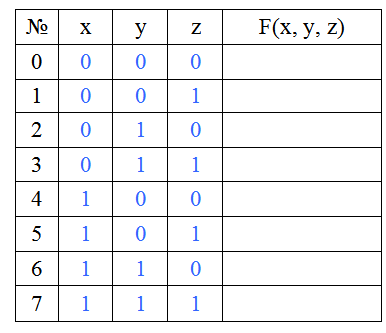
Для использования данного способа я рекомендую дополнять целевую таблицу истинности ещё одним столбцом слева. В нём мы будем нумеровать двоичные наборы, начиная с нуля (это важно). Таким образом, наша таблица истинности для трёх переменных принимает следующий вид:
Отступление. Почему надо нумеровать с нуля?
Есть, как минимум две причины, по которым это нужно делать:
- двоичные наборы нумеруются с нуля в условиях задач, решение которых предполагает работу с булевыми функциями и, в частности, работу с таблицами истинности. Например, вам может быть поставлена задача, найти МДНФ функции, заданной двоичными наборами, например, 0, 2, 6, 8, 15. Или, наоборот, найти номера двоичных наборов, на которых функция принимает значение «0». Если вы будете нумеровать наборы с единицы, то вы неверно решите задачи или не сможете решить их вообще;
- если вас интересует эта статья, то, скорей всего, вы изучаете дискретную математику или булеву алгебру. А из этого следует, что вы, возможно, обучаетесь на специальности/факультете, где параллельно изучаются дисциплины, связанные с программированием. В языках программирования сущности, являющиеся элементами коллекций или структур хранения данных (массивов, списков и так далее) также нумеруются с нуля. Я понимаю, что, если вы изучали язык Turbo Pascal, то, возможно вас учили определять массивы, нумерация элементов в которых начинается с единицы, а также, возможно, вы сталкивались с таким типом данных, как строки в этом же языке, где нумерация символов также начинается с единицы. Тем не менее, ввиду вышесказанного, вам следует привыкнуть к нумерации элементов с нуля.
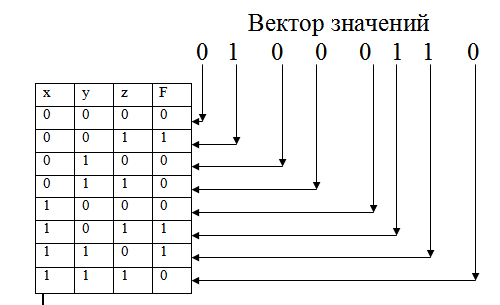
Теперь, чтобы вам было легче понимать этот способ, вспомните телевизионное шоу «Поле чудес». Там каждая буква слова записывалась в отдельной клетке. Здесь мы будем поступать так же. Только записывать мы будем не слова, а двоичные числа. Эти числа мы получим путём перевода номеров двоичных наборов из десятичной системы счисления в двоичную. Например, возьмём набор с номером 3. Переведём тройку в 2СС и получим 112. Нам надо заполнить три клетки, но полученное число состоит только из двух цифр. Чтобы данное число не изменилось, в оставшиеся пустые клетки мы можем записать только нули. Поэтому правило дополнения любого двоичного набора такое: все пустые клетки (они будут располагаться слева от заполненных клеток) заполняются нулями. После выполнения этой операции над всеми оставшимися номерами наборов мы получим следующую картину:
Чтобы закрепить полученные знания, попробуйте самостоятельно построить таблицу истинности для функции от пяти переменных: f(a, b, c, d, e)
Второй способ («по вертикали»).
В этом способе вам не потребуется дополнять таблицу столбцом с номерами двоичных наборов и переводить их в 2СС.
Чтобы понять суть метода, давайте у заполненной таблицы в двоичных наборах раскрасим нули синим цветом, а единицы — красным. Получим:
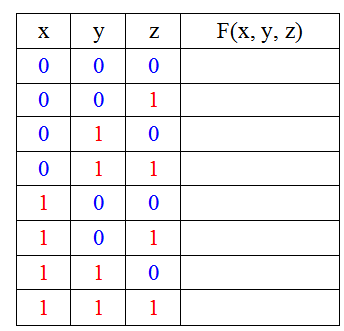
Посмотрите на столбцы. Можно заметить, что непрерывные серии из нулей/единиц чередуются, при этом длина серии (количество элементов, её составляющих) увеличивается в два раза при движении влево на каждой позиции и, наоборот, уменьшается в два раза при перемещении вправо на каждой позиции. Так, длина серии в столбце, соответствующем первой переменной (x) — максимальна и равна 4, а для последней переменной (z) — минимальна и равна 1.
В общем случае, длина серии в столбце, соответствующем первой переменной будет равна 2n / 2 = 2n-1, где n — количество переменных функции. При смещении вправо длину серии следует сокращать вдвое на каждой следующей позиции. На столбце для последней переменной длина серии окажется равной 1.
Вот вторая вариация метода. Если двигаться в обратном направлении и с другого конца (крайний правый столбец для последней переменной функции), то длинна серии в начале будет равна 1, а при движении влево её длина будет удваиваться на каждом следующем столбце, достигнув в итоге значения 2n-1 на крайнем левом столбце.
Я считаю, что преимущество такого способа состоит в быстроте заполнения. Например, все таблицы с двоичными наборами, которые были приведены в данной статье, были заполнены именно этим методом, при этом я начинал заполнение с крайнего левого столбца.
Попробуйте попрактиковаться, заполнив таблицу этим способом, решив пример для самостоятельной работы из описания предыдущего способа.
Отступление. Можно ли менять порядок двоичных наборов?
Нет, нельзя. Даже если вы верно вычислите значения функции на всех наборах, вектор значений функции у вас будет соответствовать другой функции, отличной от той, над которой вы работали. В некоторых задачах от вас может потребоваться записать вектор функции в качестве ответа. Если вы измените порядок двоичных наборов и выпишите вектор значений то получите неверный ответ и задачу вам не засчитают.
P. S. Примеры для самостоятельной работы предназначены, разумеется, для тех, кто интересуется материалом в целях обучения, а не для всех вообще, кто читает эту тему. Пусть каждый для себя сам решает, будет он решать примеры из этой статьи или нет. Материал предназначен главным образом для тех, кто хочет научиться строить и заполнять таблицы истинности.