В общем-то. Есть файлы от Excel (формата .xlsx).
По своей структуре это архив с .xml файлами.
Для того чтобы читать и изменять такие документы, решил использовать библиотеку xlnt.
Использую её из-за того, что она читает любые виды ячеек в Excel (R1C1 в частности).
Всё работает идеально, за исключение чтения русских символов.
Я думаю, что проблема не в самой библиотеке, сколько в том как я это делаю. Хотя может я и ошибаюсь.
Сами .xml файлы изначально в кодировке UTF-8, а xlnt грузит их в string тип.
Простой setlocale здесь не обойтись!
Почитал документацию, пока что особых мыслей нет, кроме как изменять код самой библиотеки.
Может кто знает как, да что?
Если чего, то код самый обычный:
#include <iostream>
#include <xlnt/xlnt.hpp>
using namespace std;
int main()
{
xlnt::workbook wb;
wb.load("t1.xlsx");
auto ws = wb.active_sheet();
cout << ws.cell("A1").value<double>() << endl; // числа читает
cout << ws.cell("B1").value<string>() << endl; // английский читает
cout << ws.cell("C1").value<string>() << endl; // а русский не читает (
system("pause");
return 0;
}
В С++ и string, и wstring это в основном просто контейнеры для байтов.
У string элемент всегда 1 байт, у wstring зависит от платформы (обычно 2 или 4). Поэтому бывает, что string удобно использовать и для хранения юникодных байтов.
Вполне возможно, что если просто вывести это в файл и открыть его текстовым редактором в UTF-8, то всё будет норм.
Лучше брать другой язык (C#, …) если хотите простой работы с юникодом из коробки
Задача состоит в том, чтобы открыть .xslx файл и считать оттуда все ячейки таблицы.
Далее данные можно использовать как угодно, для подсчёта и т.д.
Но сама проблема именно в русских символах. Мне нужно чтобы они были нормальной кодировки для последующей работы с ними.
Они скорее всего в ней и есть — UTF-8. Вопрос только что дальше с ними делать. Многие С++ библиотеки и т.д. именно в таком виде и принимают юникодные строки. Ну а в консоль винды юникод так просто не вывести.
В С++ кодировки у строк не особо есть. Есть байты, их можно конвертировать в разные кодировки. Есть сторонние библиотеки со своими более удобными строками типа Qt.
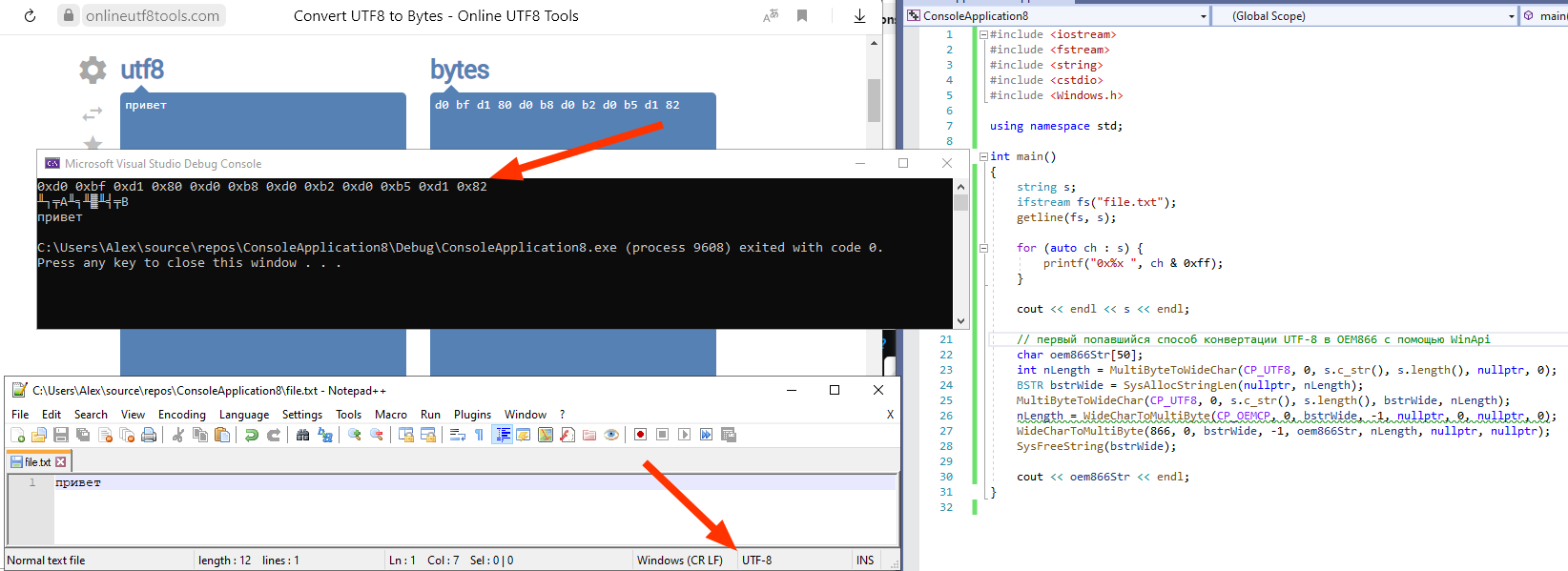
Например так без сторонних библиотек можно конвертировать UTF-8 в OEM866 для консоли винды:
#include <iostream>
#include <fstream>
#include <string>
#include <cstdio>
#include <Windows.h>
using namespace std;
int main()
{
string s;
ifstream fs("file.txt");
getline(fs, s);
for (auto ch : s) {
printf("0x%x ", ch & 0xff);
}
cout << endl << s << endl;
// первый попавшийся способ конвертации UTF-8 в OEM866 с помощью WinApi
char oem866Str[50];
int nLength = MultiByteToWideChar(CP_UTF8, 0, s.c_str(), s.length(), nullptr, 0);
BSTR bstrWide = SysAllocStringLen(nullptr, nLength);
MultiByteToWideChar(CP_UTF8, 0, s.c_str(), s.length(), bstrWide, nLength);
nLength = WideCharToMultiByte(866, 0, bstrWide, -1, nullptr, 0, nullptr, 0);
WideCharToMultiByte(866, 0, bstrWide, -1, oem866Str, nLength, nullptr, nullptr);
SysFreeString(bstrWide);
cout << oem866Str << endl;
}
Спасибо, бро. Да я всё понимаю, что string, wstring и что там байты, все дела.
Видишь как оно получается, я бы код писал на другом языке, но c++ как-то он ближе всё таки.
Не переношу на дух c# и java, хотя довольно долгое время работал с ними.
Сама база c++ у меня есть, а вот какие-либо тупиковые вещи приходится постоянно решать)
Да и своих наработок уже много, всяких костылей на разные ситуации.