Получаю ошибку: Uncaught (in promise) SyntaxError: Unexpected end of input
Если убрать {mode: "no-cors"} тогда ругается другой ошибкой. Что-то про то что у меня локальный сервер не httpsный
btnDownload.onclick = () => {
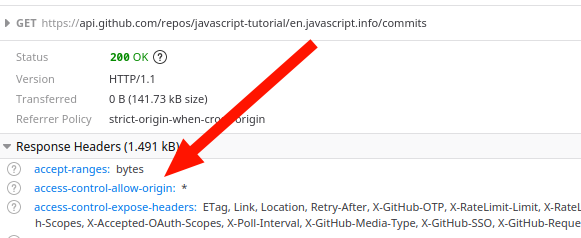
const url = "https://api.github.com/repos/javascript-tutorial/en.javascript.info/commits";
if (url === "") {
return;
}
httpGet(url);
}
async function httpGet(url) {
const r = await fetch(url);
console.log(r.status);
}
Если ввести другую ссылку, например на страницу видосика с ютуба, выдаёт: Access to fetch at 'https://www.youtube.com/watch?v=7szcXCT-Oqw' from origin 'http://127.0.0.1:5500' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
Если добавить no-cors - выдаёт код ошибки 0 на все ссылки.
Для первой её сервер указал, что можно запрашивать скриптами с любых сайтов.
Ютуб это не сделал.
CORS же нужен чтоб JS любого сайта не мог например получить страницы других сайтов, где пользователь залогинен и т.д., и как-то вредоносно использовать эти данные.
при запросе не из скрипта на странице в браузере таких проблем нет. Так же как можно зайти куда угодно введя адрес в строку браузера.
CORS защищает пользователей браузера, а не содержимое сайта.